Block Layer
The block layer is the public API for the Reference FTL and implements an asynchronous block API.
It uses the flash translation layer (FTL) to map user LBAs to device flash addresses. The properties
of a configured QoS Domain are read using SEFBlockGetInfo. The
deferMount member in struct SEFBlockOption can be set to true
to create a context to quickly access properties without having to perform a full initialization.
I/O
Block I/O is issued by calling SEFBlockIO. It places no restriction on the size of a write, but the SEF Library will break large writes up into multiple smaller writes based on device and operating system limits. There is also no restriction on the size of a read, but large reads will be broken up into smaller reads of contiguous runs of flash addresses. Typically, if data was written with one write, it can be read with one read until it crosses a Super Block boundary. However, after portions are rewritten by the client or have been moved on flash as part of a garbage collection (GC), runs can be shortened. More SEF read requests will be required to read the same data. This is handled automatically by the block layer for the caller.
As an example, this is a section of the LUT and a newly erased Super Block after two writes. The first was a write to LBA 0 of 3 ADUs in blue and the second was a write to LBA 4 of 3 ADUs in yellow.
Figure 2: Write Example 1

When a client issues a read of LBA 0 through 6, internally the block layer will need to issue 3 calls
to sbmWholeRead(). The flash addresses are contiguous, but the LBA addresses are not. The
first call will issue a read for LBA0/ADU0 of 3 ADUs, the second call will not issue a read, but
will fill the buffer for LBA 3 with zeros and the third call will issue a read for LBA4/ADU3 of 3
ADUs.
After the gap at LBA 3 is filled by a third write in green to LBA 2 of 3 ADUs, this is how the LUT and Super Block appear:
Figure 3: Write Example 2
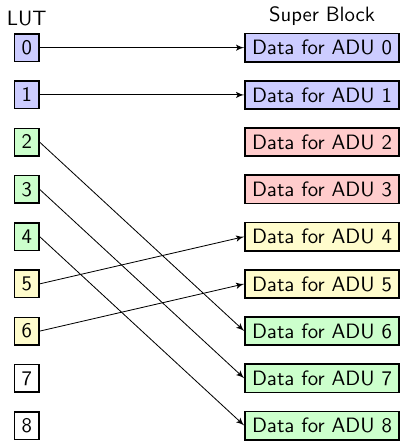
The gap at LBA 3 has been filled. ADUs 2 and 3 are colored red because they are unreachable
through the LUT and have been marked as invalid in the Super Block layer. GC skips ADUs
marked as invalid. Another result of the write is the flash addresses are no longer contiguous. A
client reading LBAs 0 through 6 will result in 3 calls to sbmWholeRead(). The first call will issue
a read for LBA0/ADU0 of 2 ADUs, the second call will issue a read for LBA2/ADU6 of 3 ADUs
and the third call will issue a read for LBA5/ADU4 of 2 ADUs.
Reads can be issued as soon as the LUT is updated, but because an SEF Unit can delay the write of data to flash, when a bad block is encountered, a previously returned tentative flash address will be asynchronously updated via the QoS Domain’s notification function. When the read of a tentative flash address has been issued against an updated flash address, it will fail and needs to be retried with the updated flash address. The block layer handles re-issuing the read using the updated flash address. See Delayed Writes for details.
I/O priority
The I/O priority used for reads and writes is inherited from the default weights configured for the
QoS Domain and read FIFOs from the Virtual Device. However, when a garbage collect is active,
the write and copy weights are adjusted by the block layer such that the throughput of read stays
unchanged. The priority of GC copies vs. writes is adjusted by sbmAdjustIOWeights at the start
of every GC-issued copy command.
Even though priority can be adjusted for every copy command, the current priority scheme is fixed and based on the worst-case WAF, which can be calculated from the amount of over-provisioning.
WAF <= 1/OP
Every user write requires GC to write WAF − 1 more.
That is, the ratio of copy to write weights has to be at least WAF − 1
to not be overrun by user writes. At the same time, the sum of the weights must be equal to the
default program weight to not affect read die time.
programWeight = defaultWeight ∗ WAF
copyWeight = defaultWeight ∗ (WAF −1) / WAF
At the end of a GC cycle, the program weight is restored to the default weight.
Delayed Writes
An SEF Unit uses delayed writes to quickly respond with a flash address but remove the burden of the client handling the program size of the device. This requires the buffer lifetime to be longer than completion of SEFBlockIO. This introduces extra overhead in the form of a buffer allocation and data copy. The impact of delayed writes can be eliminated by the client taking responsibility for buffer management.
When the flag kSEFBlockIOFlagNotifyBufferRelease is set in a struct SEFMultiContext I/O request, the caller’s buffer is used for delayed writes. That is, the buffer passed in must continue to be valid, even after the I/O’s completion routine has been called. Once the second phase of write is complete, the FTL client will receive a struct SEFBlockNotify through the notify routine supplied in struct SEFBlockOption when SEFBlockInit was called. The iov and iovcnt members describe the portion of the write buffer that is now committed to flash. A delayed write typically completes in milliseconds but can take tens of minutes to complete when there is insufficient data to fill the device’s internal write buffer. The SDK includes a sample buddy allocator that can allocate a large buffer with minimal fragments where portions of the buffer are freed at different times.
Crash Recovery
The LUT is kept entirely in DRAM by the FTL layer. If the FTL client process were to crash, the LUT and data saved on the device would be out of sync. When this happens, SEFBlockInit will fail. This can be fixed by repairing the LUT using SEFBlockCheck. Enough metadata is kept with each write to reconstruct the LUT, even when it is entirely lost.